IA en supply chain : sans données solides, pas de valeur durable

Le 26 mars dernier, agileDSS France co-organisait avec le PASCA une matinée dédiée à la data et à l’IA en supply chain, à Nantes. Le PASCA, Pôle Achats Supply Chain Atlantique, est un réseau de professionnels et d’experts dédié aux enjeux achats et supply chain en Pays de la Loire, qui fédère acteurs industriels, partenaires et institutions autour du partage de bonnes pratiques.
Au programme : comprendre les enjeux réels de l’IA aujourd’hui, poser les fondamentaux d’un socle data solide, et confronter ces réflexions à des retours d’expérience concrets issus du terrain.
Cette matinée est venue confirmer un constat que nous partageons depuis longtemps avec nos clients : avant de parler d’IA, il faut parler de data. Nous avons voulu ici vous repartager les grands axes de cette conviction.
Ce que le terrain nous apprend
Chez agileDSS France, nous intervenons depuis plusieurs années aux côtés d’organisations qui cherchent à tirer parti de leurs données et à intégrer l’intelligence artificielle dans leurs opérations. En supply chain plus qu’ailleurs, nous observons un écart persistant entre les ambitions affichées et les projets qui aboutissent réellement.
Ce n’est pas une question de technologie. Les outils sont là, accessibles, souvent matures. Ce qui fait la différence, c’est ce qui précède leur déploiement.
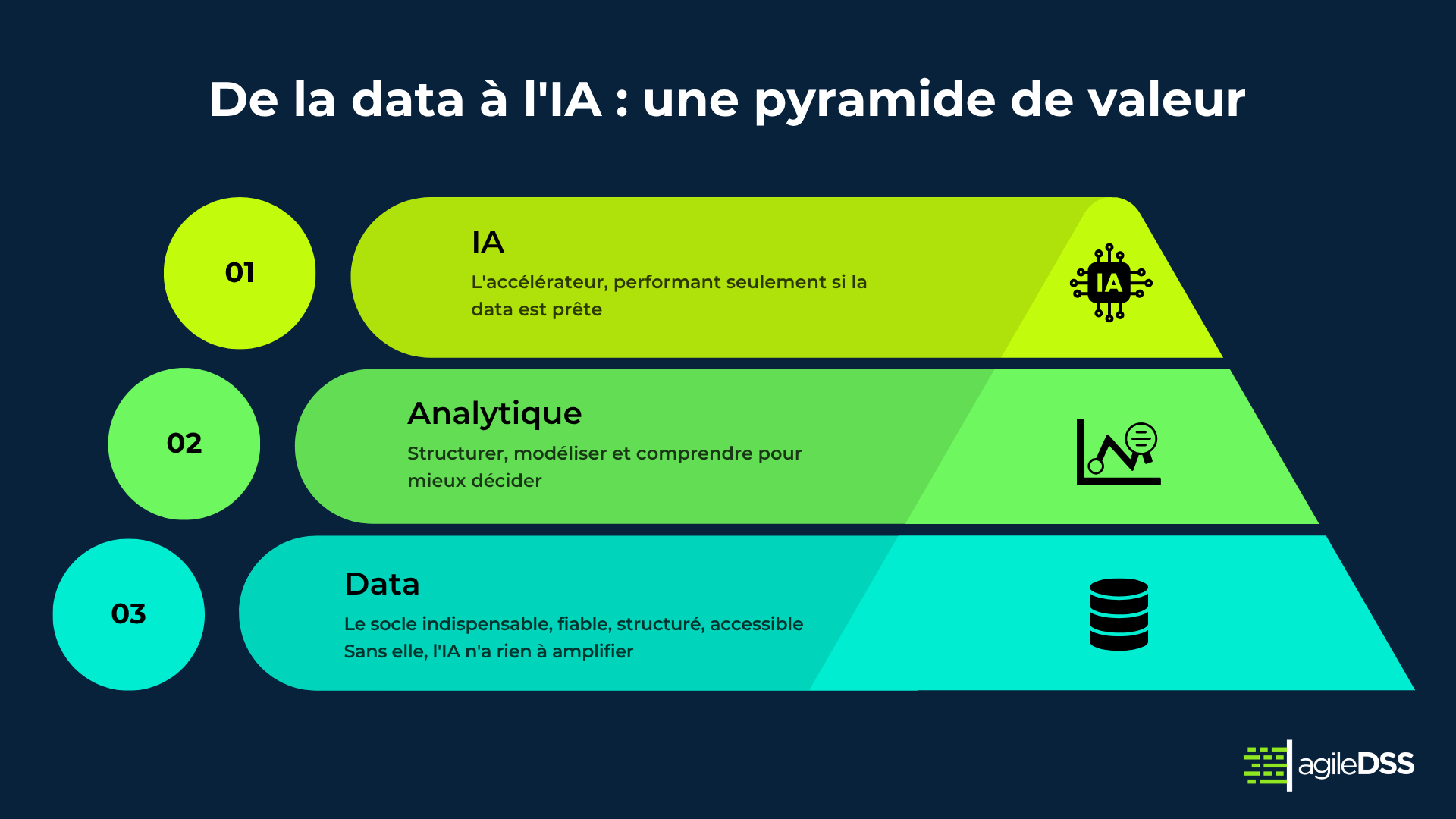
Donnée d’abord. IA ensuite.
L’IA amplifie la donnée, elle ne la remplace pas
Notre conviction centrale, celle qui structure notre approche, est simple : l’IA ne peut pas compenser une donnée défaillante. Elle l’amplifie.
Un modèle prédictif alimenté par des données incomplètes ou hétérogènes produira des résultats peu fiables, voire contre-productifs. Dans la supply chain, où les décisions ont des impacts directs sur les opérations, la qualité des données n’est pas un détail technique. C’est un prérequis stratégique.
Ce que nous observons chez nos clients
Ce que nous voyons régulièrement, en particulier dans les PME industrielles : les données existent, mais elles sont dispersées, mal structurées, ou simplement non exploitées. La première étape n’est pas de déployer de l’IA. C’est d’évaluer honnêtement ce qu’on a, de le fiabiliser, puis de construire à partir de là.
Le syndrome du POC sans lendemain
Un phénomène fréquent, des causes bien identifiées
L’un des phénomènes les plus fréquents que nous observons : des preuves de concept qui valident une idée, suscitent de l’enthousiasme, puis s’arrêtent là. Le POC a fonctionné en laboratoire. Il ne passe pas en production.
Les causes sont connues :
- Données de test trop propres, non représentatives de la réalité opérationnelle
- Périmètre trop réduit, qui ne reflète pas la complexité réelle des flux
- Intégration système non anticipée
- Manque de portage organisationnel au-delà de l’équipe projet
Penser l’industrialisation dès le départ
Pour y remédier, notre approche consiste à poser très tôt les questions d’industrialisation : quelles données en conditions réelles ? Quelle intégration avec le système d’information existant ? Qui maintient le modèle dans six mois ? Ces questions ne tuent pas le POC. Elles lui donnent une chance de devenir autre chose.
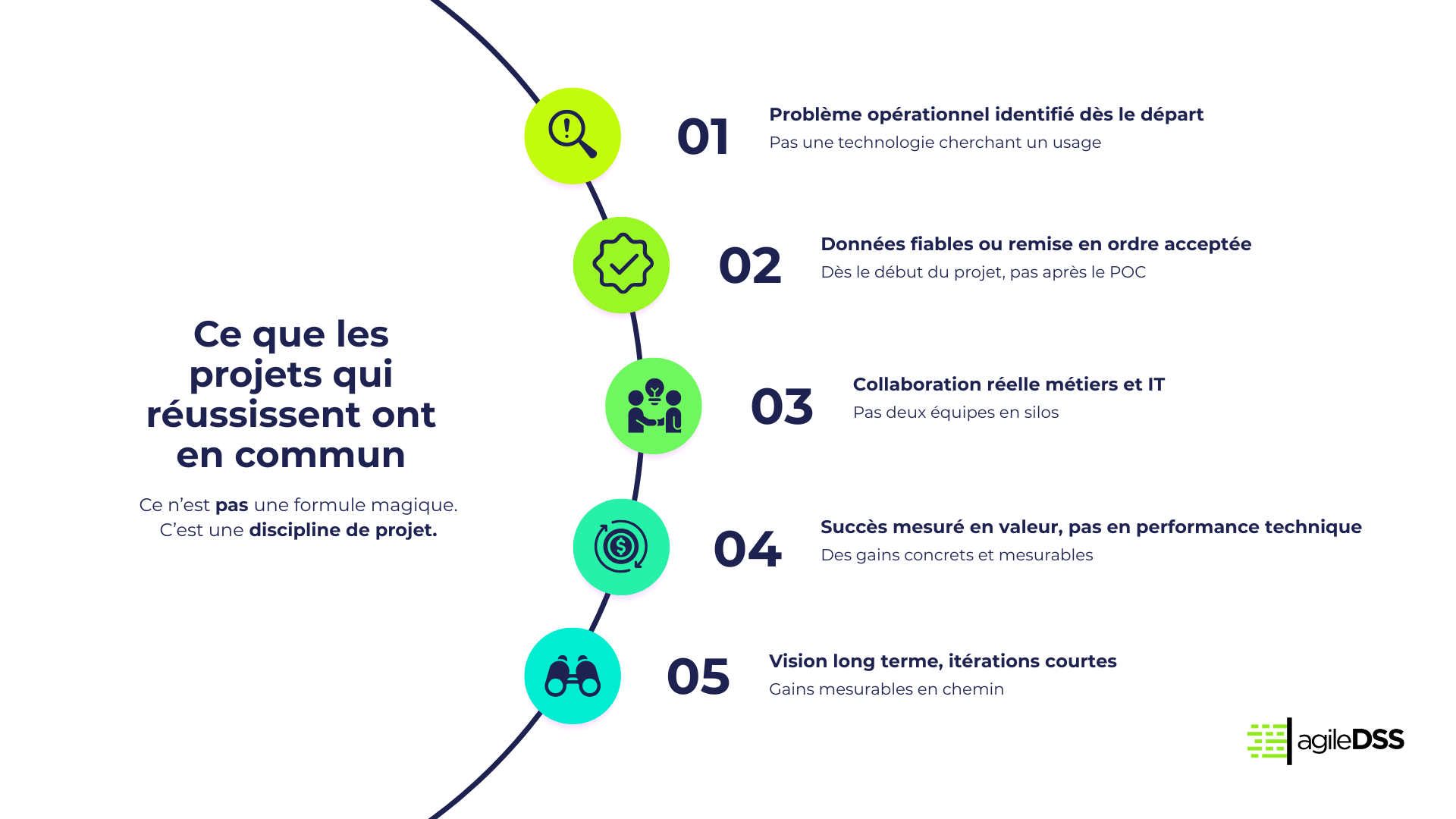
Ce que les projets qui réussissent ont en commun
En regardant les projets data/IA en supply chain qui atteignent réellement leur cible, plusieurs constantes se dégagent :
- Un problème opérationnel clairement identifié au départ, pas une technologie cherchant un usage
- Des données suffisamment fiables pour être exploitées, ou une phase de remise en ordre acceptée dès le début
- Une collaboration réelle entre les équipes métiers et les fonctions IT
- Un critère de succès défini en termes de valeur, pas de performance technique
- Une vision de long terme, avec des itérations courtes et des gains mesurables en chemin
Ce n’est pas une formule magique. C’est une discipline de projet.
Notre rôle dans cet écosystème
agileDSS France fait partie du Groupe agileDSS, acteur des données et de l’IA depuis plus de 20 ans. Notre positionnement est clair : la data est le socle d’une IA réussie. Ce n’est pas un slogan. C’est ce que nous mettons en oeuvre chaque jour, avec les organisations que nous accompagnons.
En supply chain, nous intervenons sur la structuration des données, la modernisation des architectures analytiques, l’intégration de cas d’usage IA concrets et l’accompagnement des équipes dans l’adoption de ces nouvelles pratiques.
La matinée du 26 mars a donné lieu à une synthèse complète publiée par le PASCA. Si vous souhaitez retrouver le détail des échanges, des retours d’expérience présentés et des conseils pratiques pour démarrer un projet data/IA, vous pouvez consulter leur article complet ici.
Si vous souhaitez faire le point sur votre maturité data avant de lancer un projet IA, nos équipes sont disponibles pour en discuter.
FAQ
Pourquoi la qualité des données est-elle le premier facteur de succès d’un projet IA en supply chain ?
Parce que l’IA ne crée pas de la valeur à partir de rien : elle exploite et amplifie ce que les données lui permettent de voir. Des données incomplètes, hétérogènes ou mal structurées produiront des résultats peu fiables, quels que soient les modèles utilisés. Dans la supply chain, où les décisions ont des impacts opérationnels directs, cette fiabilité n’est pas optionnelle.
Qu’est-ce qu’un POC IA et pourquoi échoue-t-il souvent à passer en production ?
Un POC (preuve de concept) permet de valider la faisabilité technique d’un cas d’usage IA. Il échoue à passer en production quand il a été construit dans des conditions trop idéales : données trop propres, périmètre trop réduit, intégration non anticipée. La clé est de penser l’industrialisation dès le lancement du POC, et non après.
Par où commencer pour structurer une démarche data/IA en supply chain ?
Par un état des lieux honnête des données disponibles : leur qualité, leur accessibilité, leur structuration. Ensuite, identifier un irritant opérationnel concret à résoudre, plutôt que de chercher un cas d’usage technologique. C’est ce point de départ qui conditionne tout le reste.
Combien de temps faut-il pour déployer une solution IA opérationnelle en supply chain ?
Un premier cas d'usage peut être opérationnel rapidement, en quelques semaines à quelques mois selon la maturité des données disponibles. Mais ce qui distingue les organisations qui tirent une valeur durable de l'IA, c'est la façon dont elles pensent la suite. Les outils évoluent, les algorithmes aussi. Ce qui ne change pas, c'est la valeur d'une architecture data bien pensée et d'une feuille de route de cas d'usage cohérente. Les organisations qui s'y investissent ne subissent pas les changements technologiques : elles les anticipent et restent en contrôle de leur trajectoire.
Other articles
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
April 2026Islam Touati
Business Intelligence
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
March 2026Adrien Chaudé et Adrien Lecellier
Business Intelligence
How LOU-TEC modernized its business intelligence with agileDSS and Power BI
February 2026Ricardo Briones