Data Vault: What's to know about this Data Warehouse vision?
This article is the first of a series explaining the Data Vault approach for data warehouse modeling.
For a couple of years, two classics visions battled for modeling data warehouse : the Inmon modeling approach by normalized subjects and the Kimball star modeling approach where the business warehouse is assured by conformed dimensions and the usage of a bus matrix.
While being less popular than the two other approaches, there is a third choice: the Data Vault modeling approach, promoted since the early 2000 by his creator, Dan Linstedt. The Data Vault modeling is a hybrid approach between Inmon and Kimball.
A Data Vault model is composed of three types of entities: hubs, links, and satellites.
Hubs are business concepts. Those entities contain the natural keys (business keys) that identify the concept and are really stable by nature. They do not contain data describing the concepts (those are kept in the satellite, which will be later described). They often constitute the linking point (hence the term “hub”) between multiple sectors of an organization. Figure 1 illustrates a Data Vault model example. The entities “Position, Job posting, Employee, and Application” are all hubs.
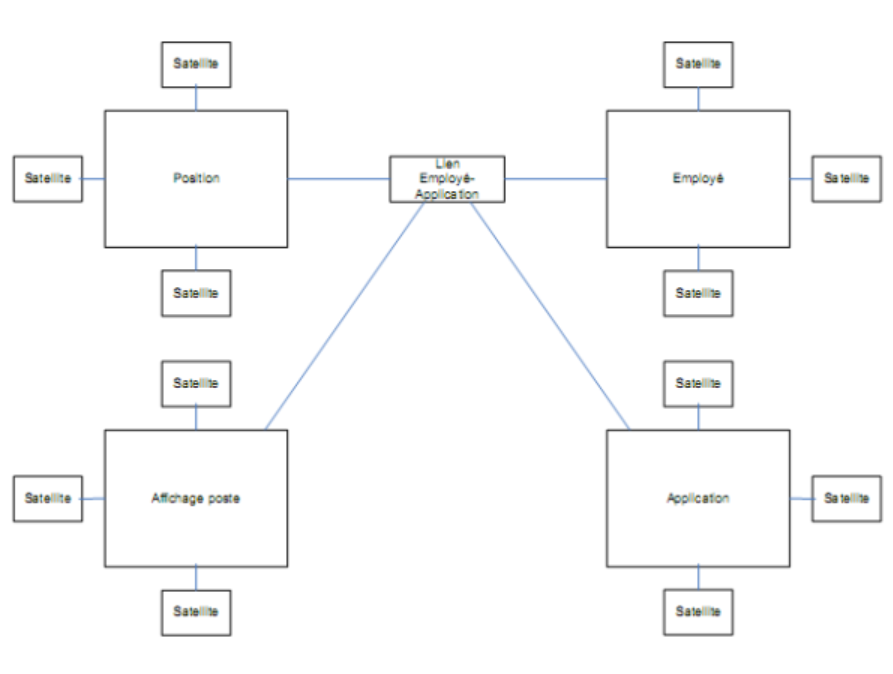
Figure 1 Example of a Data Valut Model
Links are associative entities. They link together at least two hubs which mean that they put in relation business concepts. The entity “employee-application link” in Figure 1 is a link example.
Satellites contain data describing hubs and links at a given moment and through time. Those entities include the context (coming from business processes) of a hub or a link. Though descriptive data often changes, the idea behind satellites is to conserve changes when they happen. As its name implies, a satellite is a dependant (or weak) entity that is always in relation with a hub or a link. On the other hand, a hub or a link must have at least one satellite to describe them.
One of the central idea for a Data Vault model consist of separating structural data from descriptive data defining their contexts (satellites). With this, structural concepts of an organization are separated from usage contexts of those concepts.
Another central idea of the Data Vault model is that it keeps intact the source system context. Data coming from different sources is integrated in a Data Vault type warehouse without undergoing transformations. Data is then rapidly loaded in their raw format, including the date and the modification source. It is therefore possible to rebuild a source’s image at any moment in time. The fact of not “working” the data is one of the major differences with the two other classic approaches. A Data Vault warehouse is often named a raw data warehouse.
The Data Vault approach offers multiple advantages:
- It is flexible and is modification resistant
- It is extendable
- Modifications in the sources are rapidly shown in the warehouse
- It easily allows to reconstitute data source image at any moment in time
In the following articles, we will go into more details on the motivations of this modeling approach and the Data Vault modeling. We will also compare the Data Vault approach with the star schema and the subject approaches.
Other articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
May 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
April 2026Islam Touati
Business Intelligence
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
March 2026Adrien Chaudé et Adrien Lecellier