How can you structure the unstructured with SAP Data Services?
With SAP BO Data Services version 4+, the analysis of unstructured data and its sub-discipline, Customer Sentiment Analysis (CSA), have become pretty straightforward from a technical point of view. In conjunction with one of the included dictionary files, the building block “Base_EntityExtraction” structures your text almost out-of-the-box.
However, unless you build your own dictionary, the structure created follows linguistic principles and is not at all tailored to any (business) context whatsoever. Moreover, much depends on your cleaning efforts regarding the content you’re feeding DS with. Creating contextualised, actionable information is still not – and will probably never be – a no-brainer.
Inspired by the Pareto principle, this blog post discusses an approach for implementing a sentiment analysis using a “built-in” functionality, catching a major part and taking the risk to lose some of the information in order to avoid the hoops of customising your dictionary.
Snap In > Snap Out :)
The less noisy your input, the crispier your result; we’re not spending too much time on this platitude, but we don’t want to create false expectations either. Technically, Base_EntityExtraction can be fed with any type of text file or database table (column). For this blog, we used the content of an existing forum on the web where users were sharing experiences about motorized vehicles. However, we didn’t just save the HTML code, but we extracted the “pure” content and saved it into a .txt file. This might be a best-case-scenario, but as we’re not aiming at discussing classic ETL and cleansing problems, we hope it is a pertinent simplification.
The Job That Does the Job
There are basically two schools of thought: you can implement a lot of logic in DS and only store a boiled-down result in your database for analysis, or you can just implement what’s absolutely necessary in the prior and keep it more at your disposal in the latter.
From an analyst’s point of view – probably your clientele when you’re implementing unstructured text analysis – it is preferable not to decide too early what data to ignore and what not. For this and other reasons, such as the flexibility and transparency that comes with it, we favoured to let DS just do the dirty work and implement any intelligence later. However, if you face constraints because your output table is getting too big, it’s probably worth going for a compromise: filter out what’s definitely not of interest but leave enough to not feel constrained afterwards.
As a consequence, our DS job looks deceivingly simple:
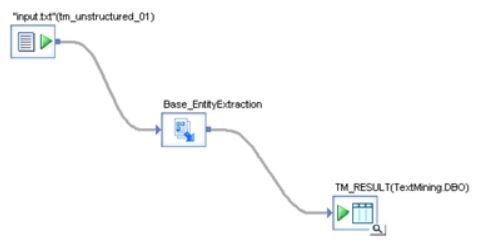
Don’t forget to activate sentiment analysis in Base_EntityExtraction:

Simple jobs usually leave you with a lot of aftermath; in this case we’re getting surprisingly far...
Sentiments and Entities
If you’re using a template table, your result will look more or less like this:

The column type is where all the classification drops in. The values you will find there can be split into two main groups: sentiments and other “entities”. The following table lists all available out-of-the-box sentiments:

Using the ID and PARENT_ID columns, these sentiments can easily be linked back to what the sentiment is about. For example, the sentiment “great” in line 33 is linked back to the parent in line 31, which is also the parent of the topic “Automatic transmission” in line 32. So far, so out-of-the-box, and keep in mind that this works without any customisation for the business context!
However, things are not always as clear as that. For example, the (probably more important) Weak Negative Sentiment about the clutch in line 35 is not so negative after all and neither can it be simply related to the Topic “clutch” as in the above case. Line 37 is comparably forgiving, where “very nice” is just linked to more than one topic. In many cases, the product or object of interest will not be properly tagged, as there are many other pertinent high-level entities without customisation.
Bottom Line
Keeping in mind that our input file was already very clean, it is easily imaginable that we have to deal with quite a number of situations before we get actionable information on what’s good or bad with our products. One of the most important steps might be customisation, but if you have massive amounts of data, an out-of the box solution might actually create very valuable insights.
Stay tuned for the next blog in which we will provide you with more information on the entities available and demonstrate a one-size-fits-all implementation avoiding customisation that gets your text analysis project going within minutes.
Other articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
May 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
April 2026Islam Touati
Business Intelligence
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
March 2026Adrien Chaudé et Adrien Lecellier