Data Vault : Bonnes pratiques pour créer des satellites - Partie 4
Cet article est le quatrième d'une série d’articles traitant d’une alternative à la modélisation d'entrepôts de données : l'approche Data Vault.
Dans le premier article, nous avons globalement présenté l’approche Data Vault et les trois types d’entités de cette approche : les hubs qui identifient les concepts d’affaires utilisés par un ou plusieurs secteurs de l’organisation, les liens qui associent les concepts d’affaires et les satellites qui décrivent et contextualisent les hubs et les liens.
Dans le deuxième article et le troisième article, nous nous sommes attardés plus spécifiquement aux hubs et aux liens. Ce quatrième article traite des satellites.
Un satellite est une entité dépendante contenant les informations détaillées concernant un hub ou un lien. Elle contient l’historique des changements de ces informations descriptives et contextuelles. D’une certaine façon, on peut dire qu’elle est la partie entrepôt de données du modèle Data Vault.
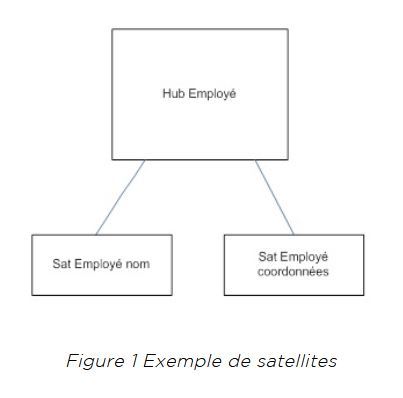
La figure 1 montre un exemple de satellites. Le hub Employé est décrit par 2 satellites : un satellite Employé nom contenant les informations nominatives de l’employé et un satellite Employé coordonnées qui contient les adresses et numéros où rejoindre l’employé.
Voici des critères à respecter pour être un bon satellite. Un satellite :
- Est en relation de dépendance avec un et un seul hub ou bien un et un seul lien; la relation est implantée par une clef étrangère qui pointe vers l’identifiant interne du hub ou du lien auquel il appartient;
N’est jamais en relation avec un autre satellite (autrement dit, un satellite n’est jamais le parent d’une relation); - Peut être divisé en plus d’un satellite par type (classification), par vitesse de changement (les données qui changent à un rythme différent sont séparées pour éviter la redondance des données qui changent moins rapidement) et par source de données pour simplifier le chargement;
- Contient toujours au minimum deux informations permettant la traçabilité : la source d’où provient la description et quand l’instance descriptive a été amenée dans l’entrepôt;
- Contient l’historique de l’entrepôt et peut contenir dans certains cas plusieurs instances actives (une sous-séquence est alors nécessaire pour assurer l’unicité des instances).
Pour des raisons de performance, il est parfois souhaitable de regrouper dans une image prise à intervalle régulier (exemple : journalièrement) la clef de la table parente et la date de chargement de l’instance courante (au moment de la prise d’image) pour chacun des satellites d’un même parent. Cette façon de faire permet une vue consolidée des satellites et en simplifie l’interrogation (bien que l’interrogation ne soit pas le but premier d’un entrepôt de données brutes…). Cette structure est appelée PIT pour « Point In Time ». Dans notre exemple, on pourrait utiliser une table « PIT Employé » qui contiendrait l’identifiant interne du hub Employé et les dates de dernier chargement des deux satellites ensemble avec la date de prise d’image.
Mentionnons finalement qu’un autre regroupement dans une image appelée « Bridge », encore utilisé pour des raisons de performance et de simplicité d’accès, combine cette fois-ci des hubs et des liens dans une même structure.
Autres articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati
Intelligence d'affaires
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
Mars 2026Adrien Chaudé et Adrien Lecellier