Quelle est la différence entre Data Lake et Data Vault?
On parle depuis quelque temps déjà de la notion de Data Lake (DL). Récemment, deux questions pertinentes m’ont été posées :
- Est-ce qu’il existe un lien entre une structure Data Vault (DV) et une structure DL?
- Est-ce qu’un DV peut aider à implanter un DL?
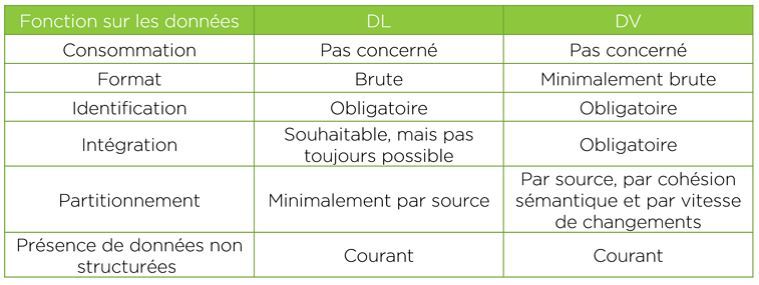
Comme souvent en informatique, la signification du terme DL est très galvaudée. Dans cet article, nous adoptons la définition suivante d’un DL : un dépôt de données brutes (maintenues dans son format d’origine), souvent non structurées (exemples : une vidéo, un texte) et provenant de différentes sources. Les DL sont souvent utilisés dans des contextes Big Data. Ils ne se préoccupent pas de comment les données vont être consommées. L’idée est d’y ajouter des données de façon asynchrone par rapport à des transformations et des usages de celles-ci. Il n’est, de toute façon, pas toujours possible d’envisager l’ajout et la transformation de données au fur et à mesure, étant donné le volume et la fréquence des données accumulées dans un contexte Big Data. La seule opération obligatoire pour un DL est l’identification des données : de quoi on parle, quelle en est la source et de quand datent les données.
De son côté, un DV est un environnement d’intégration depuis différentes sources de concepts d’affaires communs appelés « hubs » (exemples : un abonné, un véhicule) et de liens inter-concepts (la réservation d’un véhicule par un abonné). Les hubs et les liens contiennent leur identification d’affaires (exemple : le numéro d’abonné). L’historique de la description des concepts et des liens inter-concepts est stocké systématiquement dans des satellites de ceux-ci. Il y a souvent plus d’un satellite pour un concept ou un lien. Typiquement, il y aura partitionnement des satellites par source, par cohésion sémantique (exemple : les différentes coordonnées d’un abonné) et, pour normaliser un peu plus, par vitesse de changement. Dans sa version brute, il n’y a aucune transformation de données, il n’y a que de l’intégration.
Revenons maintenant à notre question : comment les deux notions de DL et de DV se rejoignent? Comme un DL, un DV ne se préoccupe pas de consommation. Dans les deux cas, les données sous leur forme brute (sans transformations) sont conservées et l’ajout de données est donc très rapide. Les données brutes sont par la suite et de façon asynchrone transformées et se retrouvent dans une structure dimensionnelle ou analytique plus propre à la consommation. Identifier quelles données se retrouvent dans le DL veut simplement dire à quel concept (exemple : une personne dans Linkedin) ou lien inter-concepts (exemple : l’appartenance d’une personne à un groupe d’intérêts) la donnée correspond.
Les deux seules choses qui différencient un DL d’un DV sont l’intégration des concepts et des liens inter-concepts depuis différentes sources et la structure d’un DV : la séparation entre l’identification (hubs et liens) et la description (satellites) et le partitionnement possible des satellites. Le DL identifie ses données, mais ne les intègre pas nécessairement. Le seul partitionnement d’un DL est, de facto, par source, puisqu’on y dépose des données pour chaque combinaison de concept (ou lien inter-concepts) provenant d’une source.
Toutefois, si le volume et la fréquence d’ajout de données ne sont pas trop grands, il est possible d’utiliser une structure DV pour un DL : intégrer les concepts et les liens inter-concepts comme à l’habitude et, minimalement, partitionner les satellites des hubs et des liens par source de données.
Autrement, s’il n’est pas possible d’intégrer l’ajout de données directement dans un DV, un DL distinct, où les données y sont uniquement identifiées et partitionnées par source, est utilisé. L’intégration asynchrone dans une structure DV pourra se faire rapidement dans un deuxième temps. Évidemment, il est possible d’adopter une approche hybride : directement dans un DV autant que possible et préalablement dans un DL dans les cas où l’intégration immédiate est impossible.
Certains peuvent argumenter que les DL contiennent des données non structurées (une vidéo par exemple), contrairement au DV qui contient des données structurées (sous forme relationnelle). Mais, même dans le cas de données non structurées, celles-ci peuvent être classifiées selon un sujet d’intérêt pour l’organisation et ce sujet d’intérêt est justement un concept d’affaires ou un lien inter-concepts. On peut donc insérer ces données non structurées dans un mode brut, soit dans un DL structuré en DV ou dans un DL suivi d’une intégration dans un DV. Comme le stockage de données non structurées n’est pas toujours évident dans un SGBD relationnel, ce sont souvent des pointeurs (exemple : URL) vers un environnement de stockage plus approprié qui seront stockés dans les satellites. Par la suite, on pourra appliquer des traitements (exemple : une analyse de sentiments) pour faire ressortir des métadonnées et stocker celles-ci dans un business DV ou une structure dimensionnelle.
Le tableau suivant résume la comparaison entre un DL et un DV.
Autres articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati
Intelligence d'affaires
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
Mars 2026Adrien Chaudé et Adrien Lecellier