Mes 3 coups de coeur du Power BI World Tour 2018 : Partie 1 - Big Data
Cette année, le Power BI World Tour 2018 s’est arrêté dans huit villes à travers le monde. C’est à l’occasion de son passage à Montréal les 14 et 15 novembre derniers, que je m’y suis rendue, en tant que Responsable de Pratique Microsoft chez agileDSS. Au menu, des conférences et ateliers pour tous: analystes, nouveaux utilisateurs de Power BI, experts, lignes d’affaires et développeurs\Admin TI.Cette année, le Power BI World Tour 2018 s’est arrêté dans huit villes à travers le monde. C’est à l’occasion de son passage à Montréal les 14 et 15 novembre derniers, que je m’y suis rendue, en tant que Responsable de Pratique Microsoft chez agileDSS. Au menu, des conférences et ateliers pour tous: analystes, nouveaux utilisateurs de Power BI, experts, lignes d’affaires et développeurs\Admin TI.
L'ensemble des conférenciers ainsi que les experts de chez Microsoft nous en ont mis plein la vue. Les conférences traitaient autant des nouvelles fonctionnalités que de celles en preview, ainsi que de la vision de Microsoft concernant la plateforme Power BI. Dans ce blog, je vais vous présenter mes trois coups de cœurs concernant les nouveautés annoncées:
- Power BI sur des milliards de lignes (sur du Big Data)
- AI et cognitive services sur Power BI
- Automated Machine Learning dans Power BI
Passionnant non? Allons voir tout ça de plus près!
Mon premier coup de cœur du Power BI World Tour 2018:
Robert Luong, spécialiste technique Data & AI chez Microsoft, nous a présenté une architecture Power BI qui permet de se connecter et de traiter des Petabytes de données, tout en gardant une haute performance. Dans la démonstration présentée, les interactions avec les visuels avaient des temps de réponse instantanés. Alors, comment était-ce possible? Simplement, en combinant les quatre nouvelles fonctionnalités suivantes:
- Modèle composite
- Dual Storage Mode
- Relations many-to-many
- Aggregations
Ces nouvelles fonctionnalités ont amené la modélisation sur Power BI à un autre niveau. Je vous les résume brièvement dans ce blog (des liens vous seront fournis pour accéder à davantage de détails).
Modèle composite
Pour comprendre qu'est-ce qu'un modèle composite, il est important de connaître les deux principaux modes de connexion sur Power BI:
Mode Import : lorsqu’on se connecte à une source de données en utilisant ce mode, les données sont copiées dans la mémoire cache de Power BI (l’engin in-memory xVelocity). Il faut effectuer des rafraîchissements manuels ou programmés si on veut voir les changements dans la source de données.
Mode Direct Query : c’est une connexion directe à la source, les données ne sont pas importées dans Power BI. Toutes les données qu’on voit dans les visuels sont à jour (pas besoin de rafraîchir). À chaque interaction avec les visuels, Power BI soumet des requêtes vers la source de données directement (ce qui peut impacter la performance).
Chaque mode a ses avantages et ses limites, c’est pourquoi chaque mode peut convenir dans certains cas et pas d’autres. Par exemple, on utilise Direct Query lorsque :
- Les données changent continuellement et qu’on a besoin d’un reporting presque en temps réel,
- Lorsque le volume de donnée est trop gros pour être importé dans la mémoire cache,
- Ou encore, lorsqu’on a besoin d’utiliser la sécurité RLS définie à la source.
Par contre, Direct Query ne permet de se connecter qu’à une seule source de données à la fois (contrairement au mode Import pour lequel c’est illimité). De plus, la performance est moins bonne qu’avec le mode Import car elle dépend de la source à laquelle on se connecte.
Un modèle composite est un modèle hybride, grâce auquel on a la possibilité de configurer certaines sources\tables avec le mode Direct Query et d’autres en mode Import. Il permet aussi de combiner les données de plusieurs sources Direct Query (on n’est plus limité à une seule source).
L’astuce c’est de configurer les grosses tables en mode Direct Query, et les plus petites en mode Import.
Pour tester cette fonctionnalité, je me suis connectée en mode Direct Query sur une table de fait contenant les détails de transactions, et sur un fichier Excel en mode import.
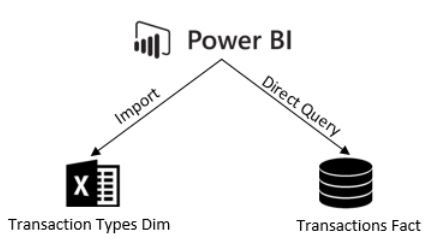
Et là, on peut voir au niveau de la barre de statut, en bas à droite du rapport, que la connexion est en Mixed mode:
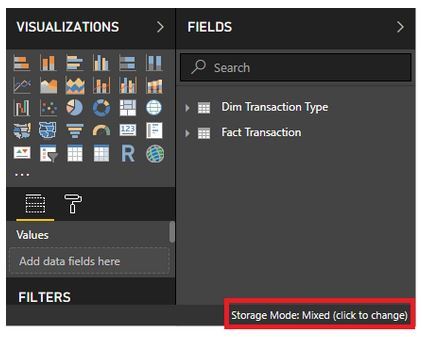
Dual Storage Mode
Le Storage Mode permet de contrôler le mode de stockage de chaque table individuellement (c’est-à-dire: est-ce-que la table sera stockée in-memory ou pas). Le Dual Storage Mode est un nouveau mode qui vient avec la fonctionnalité de Composite Model. On peut voir\modifier le mode de stockage d’une table à partir de ses propriétés.
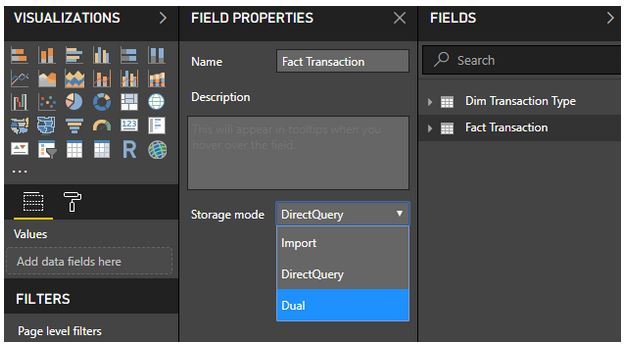
Une table configurée avec le mode Dual est une table qui sera capable d’utiliser la mémoire cache (import) ET d’exécuter les requêtes à la source (Direct Query), selon ce qui est le plus optimal (dépendamment du contexte de la requête du visuel).
Lorsqu'une table X est reliée à une table Y (configurée en mode Import) ET à un table Z (configurée en mode Direct Query) , la table X devra être en mode Dual.
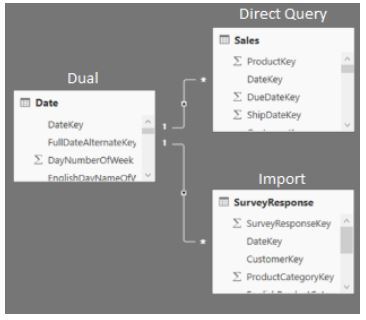
À savoir: Power BI Desktop inclut une assistance qui aide à identifier les tables qui doivent être configurées en mode Dual. Pour plus d’informations c’est par ici.
Relations many-to-many
Avec les Composite Models on peut créer des relations de cardinalité Many-to-many entre deux tables. Ce type de relation est supporté entre une table en mode Import et une autre en mode Direct Query.
La possibilité de créer des relations many-to-many entre deux tables enlève deux contraintes :
- Les solutions de contournement comme la création de tables Bridges
- L’obligation qu’au moins une des colonnes clés de la relation contienne des valeurs uniques
Avec ces relations many-to-many, on peut appliquer des filtres bidirectionnels. Mais attention, cette fonctionnalité est à utiliser avec précaution sinon vous risquez d’avoir de mauvaises surprises. Par exemple, certaines fonctions DAX ne seront plus utilisables avec ce type de relation ou leur comportement sera différent. Je vous conseille donc de bien vous documenter là-dessus avant de les utiliser.
Comment créer les relations many-to-many? On les crée au niveau de la page créer/modifier une relation (entre deux tables).
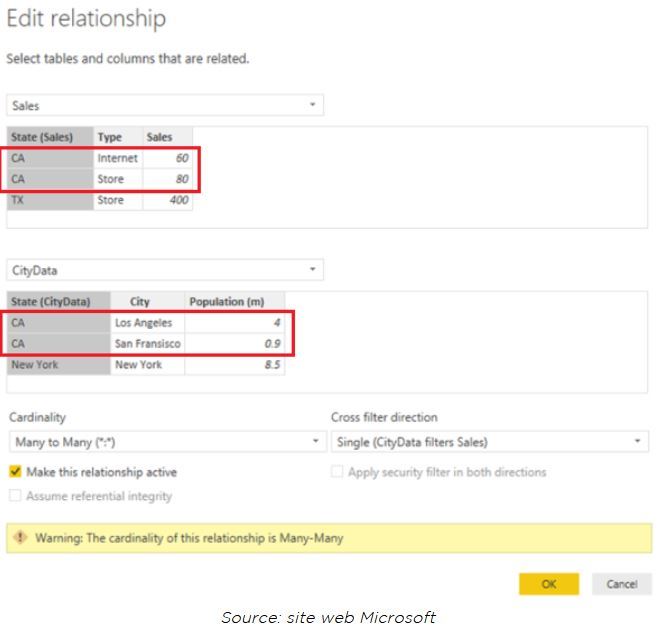
Pour plus d’informations, c’est par ici.
Power BI Aggregation
Cette fonctionnalité vient pallier au problème de lenteur du Direct Query, dans un modèle composite. Elle crée des couches de données pré-agrégées qui vont être stockées in-memory.
N’oublions pas notre objectif de départ qui est d’avoir des analyses interactives sur du Big Data. Je vous avais dit que grâce à quatre fonctionnalités, reliées entre elles, vous pouviez désormais traiter du Big Data avec Power BI, tout en conservant une haute performance. Parmi ces quatre fonctionnalités, Power BI Aggregations est celle qui vous permet d'accélérer la performance des requêtes sur des données massives.
Prenons l’exemple utilisé par Microsoft dans ses démos: une table de ventes contenant des Milliards de lignes. Cette table ne peut pas être configurée en mode import. Voici, dans les grandes lignes, la démarche à suivre: (vous trouverez plus de détails ici)
- Configuration de la grosse table détaillée Sales, en mode Direct Query
- Création d’une ou plusieurs tables d’agrégation (Sales Agg)
- Configuration de Sales Agg en mode Import
- Configuration de la fonctionnalité Aggregations sur la table Sales Agg
- Création des relations many-to-many (si nécessaire)
- Ces tables d’agrégation sont non visibles par l’utilisateur
- Les dimensions partagées par la table de détails et par les tables agrégées, doivent être de type Dual
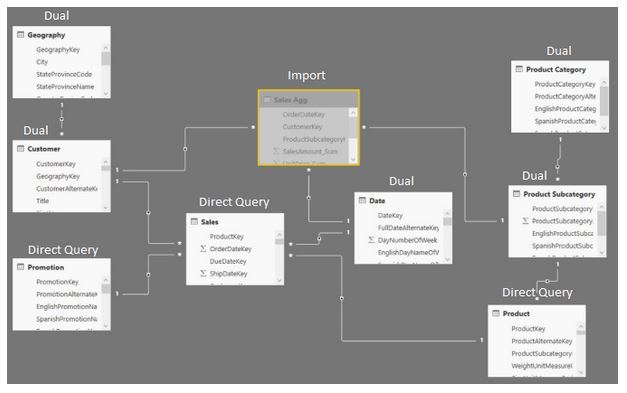
Power BI va interroger les données de la couche pré-calculée qui sont in-memory et ne fera appel à la table de détails (qui elle, est en mode Direct Query) que si les tables agrégées existantes ne répondent pas au besoin du visuel qui envoie la requête.
Création des tables d’aggregation
La table Sales Agg sera moins granulaire que Sales (elle utilisera des Group by, SUM, COUNTS etc.). Comment choisir les agrégats? Pour le savoir, posez-vous ces questions :
- Quelles seraient les requêtes les plus fréquentes des utilisateurs?
- Qu’est ce qui a le plus de valeur d’affaires?
Deux façons de créer ces tables :
- Dans la Base de données, via l’ETL
- Une expression M
Par la suite, au niveau de Power BI Desktop, on configure sur la table créée, la fonctionnalité Aggregations :
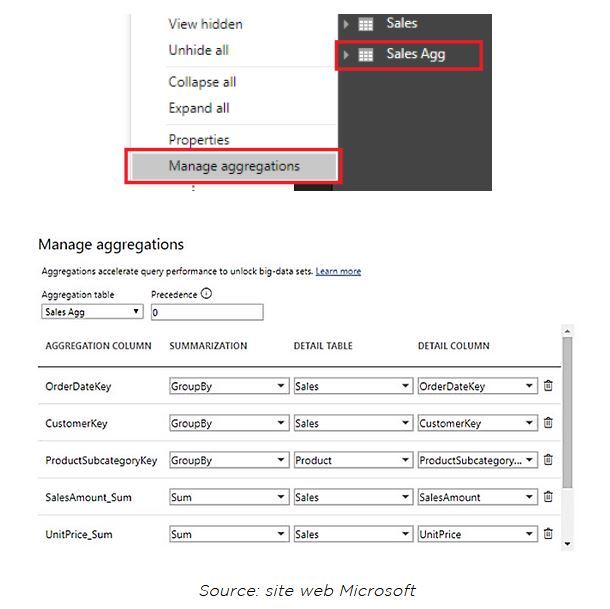
Les requêtes soumises à la table de détails Sales, par les visuels, seront redirigées en interne par Power BI vers la couche pré-calculée Sales Agg (lorsque cette dernière répond au besoin).
Pour en savoir plus, c’est par ici.
Je vous recommande aussi la vidéo suivante : Unlock petabyte-scale datasets in Azure with aggregations in Power BI.
Architecture finale proposée lors de la conférence
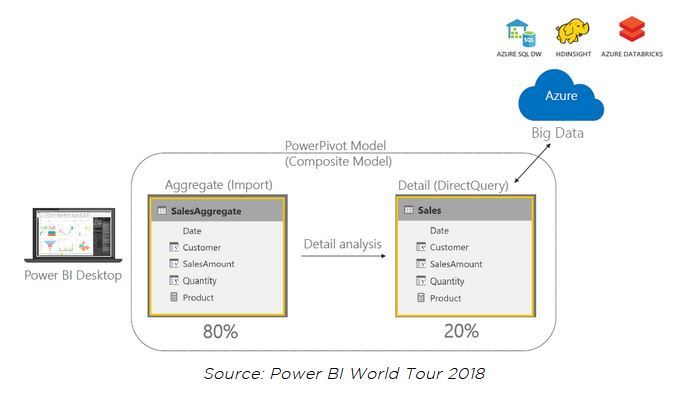
Il s'agissait donc ici de mon premier coup de cœur lors du Power BI World Tour 2018. Mon constat est que, pour cette fonctionnalité, Microsoft a principalement travaillé deux aspects:
- La modélisation (plus facile, plus flexible et plus enrichie)
- La performance (dont le catalyseur est Power BI Aggregations)
À l’ère du Big Data, cette fonctionnalité sera sans doute très appréciée de la communauté d'utilisateurs, moi la première !
Autres articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati
Intelligence d'affaires
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
Mars 2026Adrien Chaudé et Adrien Lecellier