Comment intégrer BI et Big Data
Comme bien souvent avec les nouvelles technologies, des déclarations du style « Avec le Big Data, les entrepôts de données classiques n’ont plus leur raison d’être » sont colportées. En réalité, le Big Data ne remplace pas, mais plutôt prolonge le BI dit « classique ».
Dans cet article, nous verrons comment le Big Data complémente et augmente le BI classique et comment il est possible d’intégrer celui-ci dans votre organisation.
Pour bien situer le Big Data, reprenons en premier lieu les différentes approches d’intégration.
Approches d’intégration
Extractions non structurées
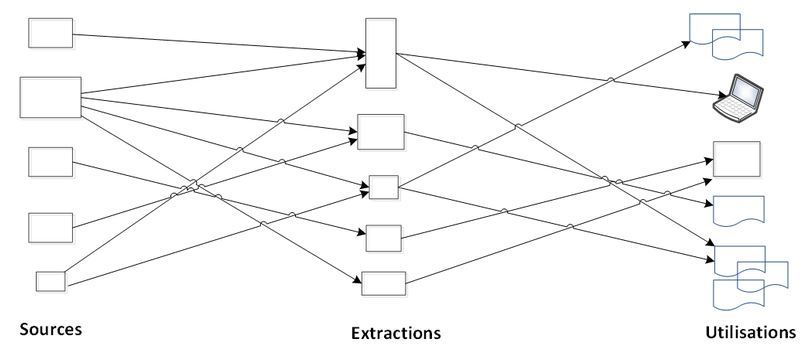
Les extractions non structurées sont caractérisées par de multiples extractions de données répliquées depuis différentes sources avec les mêmes données, souvent extraites plusieurs fois. Le gros (et le seul !) avantage de cette approche est l’ajout rapide d’une nouvelle extraction. Par contre, il n’y a ni vision intégrée (les extractions sont ajoutées selon les besoins du moment) ni harmonisation.
ETL
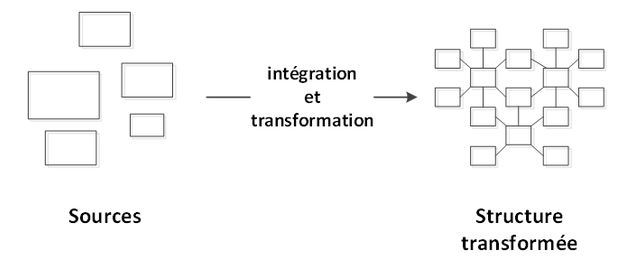
Pour contrer le manque de cohérence, l’approche ETL classique centralise l’intégration et les transformations. Bien que très en vogue, cette façon de faire est problématique, car les transformations sont longues et coûteuses et l’entrepôt de données évolue lentement. Les consommateurs de données vont donc souvent se tourner vers des solutions de contournement et finalement revenir aux extractions non structurées.
ELT
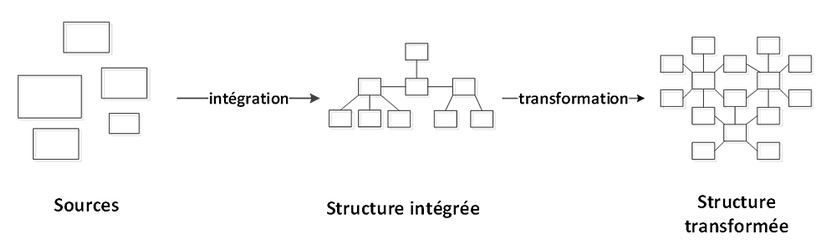
Les problèmes de l’approche ETL classique peuvent être sensiblement soulagés avec l’approche ELT qui divise les traitements en deux parties : les données sont tout d’abord intégrées dans leur état brut et conservées dans un environnement structuré ; puis, elles sont dans un deuxième temps transformées vers une structure de consommation.
L’approche ELT permet non seulement une approche intégrée et cohérente, mais elle permet aussi d’avoir plus rapidement des données brutes dans l’entrepôt.
Toutefois, même avec une approche ELT, une approche centralisée de stockage et de traitements dans un entrepôt de données classique peut devenir un goulot d’étranglement dans le cas d’écritures intensives ou quand l’environnement est mal adapté au stockage et au traitement d’informations non structurées.
C’est à ce moment que l’ajout d’une approche Big Data prend tout son sens. Celle-ci, d’une part, distribue le stockage et les traitements sur une grappe de machines et, d’autre part, sépare le stockage de la consommation en mode ELT dans une architecture Lambda, tout en isolant les traitements complexes demandant une faible latence.
Regardons maintenant différentes façons d’intégrer le Big Data à l’environnement BI existant.
Possibilités d’intégration BI - Big Data
Intégration parallèle
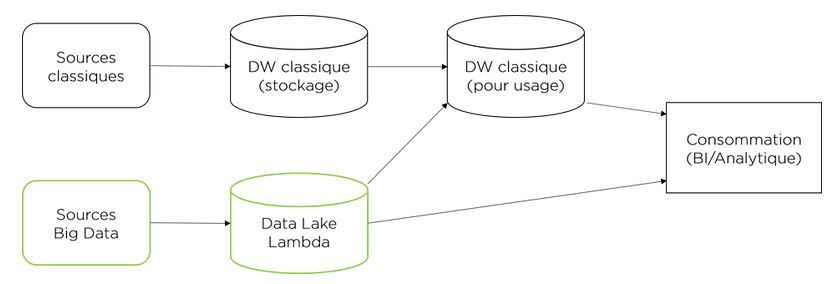
Avec l’approche parallèle, toutes les sources classiques continuent d’alimenter un entrepôt classique (en mode ETL ou ELT) alors que les sources Big Data (écriture intensive et/ou format non structuré) alimentent en parallèle un environnement Big Data Lambda. Par la suite, l’intégration s’effectue soit dans un entrepôt classique orienté consommation ou directement avec les outils de consommation.
Cette approche est moins intrusive et donc plus facile à mettre en œuvre. En contrepartie, l’intégration est moins bonne : il y a plus d’une façon d’interfacer avec les sources et plus d’intégration pour la consommation en aval.
Ce type d’intégration va souvent être celui privilégié par une organisation qui a déjà un environnement BI classique important et qui veut consolider son investissement en y incorporant des sources Big Data.
Intégration sérielle
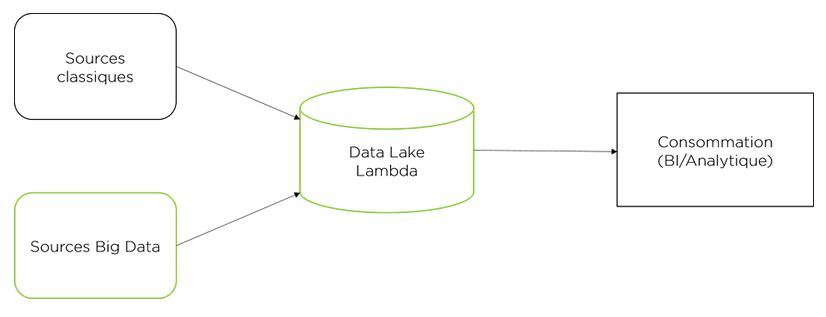
À la limite, il est possible d’utiliser uniquement un Data Lake comme entrepôt de données et consommer directement à partir de celui-ci. La plupart des outils de consommation connus ont maintenant des connecteurs qui rendent plus ou moins transparentes les requêtes adressées au Data Lake, en comparaison avec un entrepôt de données classique. C’est en principe la meilleure intégration possible, mais elle requiert l’ajout de la conversion des traitements existants de consommation. De plus, la maturité des connecteurs reste à ce jour un facteur à considérer.
Approche transitionnelle
L’intégration en série ou l’architecture Lambda seule vont souvent être considérées dans des organisations avec peu ou pas de BI ou dans des cas de refonte majeure d’un environnement existant. L’intégration en série requiert plus de composantes, mais elle permet une consommation à partir d’un environnement plus classique. Elle peut également être une transition vers une éventuelle architecture Lambda seule.
S’il y a présence significative de BI, une transition est possible d’une approche parallèle vers une approche sérielle, voire même éventuellement vers une approche purement Data Lake.
Finalement, l’avènement du Big Data sera vécu le plus souvent non pas comme un remplacement, mais plutôt comme une extension des environnements BI existants, soit parce qu’on veut bénéficier d’une plus grande vélocité de traitements et/ou d’une plus grande variété de données, ou simplement afin de tirer profit d’un environnement flexible à faible coût comme point d’entrée dans un entrepôt de données. Une telle transition nécessitera au préalable l’établissement d’une feuille de route BI - Big Data en bonne et due forme.
Autres articles
Intelligence d'affaires
Ni temps-matériel, ni forfait rigide : le modèle de partage de risque d'agileSquad
Juillet 2026Etienne Faribault
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati