Architecture Big Data Lambda : une approche agnostique
Le Big Data est le plus souvent présenté du point de vue d’environnements comme Spark et Hadoop, de plateformes telles que Hortonworks et d’outils tels que Pig et Hive. Il y a toujours des considérations spécifiques à chacune de ces technologies, mais une question se pose : existe-t-il des pratiques réutilisables dans toute solution Big Data, indépendamment des environnements spécifiques mentionnés ci-dessus? La réponse est oui, d’un point de vue d'architecture d’intégration, ces pratiques existent et on peut les regrouper sous l’appellation Architecture Lambda.
Une architecture classique est composée de bases de données centrales qui sont mises à jour incrémentalement. Même sans le Big Data, ce type d’architecture est souvent problématique, car :
- À partir d’un certain moment, l’évolutivité est difficile à obtenir
- Il y a risque de pertes de données à cause d’indisponibilités et d’erreurs humaines
- La complexité de maintenance et d’utilisation augmente avec le temps
- Il y a une latence importante entre le moment où la donnée est extraite et le moment où celle-ci est prête à être consommée avec une simplicité et une performance suffisante
- Il est difficile d’obtenir au même endroit à la fois l’évolutivité, la robustesse et la simplicité
Avec la réalité « write-heavy » du Big Data, la problématique d’une telle approche est amplifiée. L’approche centralisée de stockage et de traitements ne suffit plus. Il faut alors d’une part utiliser une approche distribuée sur des grappes de machines et d’autre part séparer fonctionnellement le stockage, la consommation et le traitement complexe en temps réel. C’est ce que propose l’architecture Lambda qui se découpe en trois parties :
- La couche batch
- La couche service
- La couche performance (« speed layer »)
L’architecture est illustrée à la figure 1.
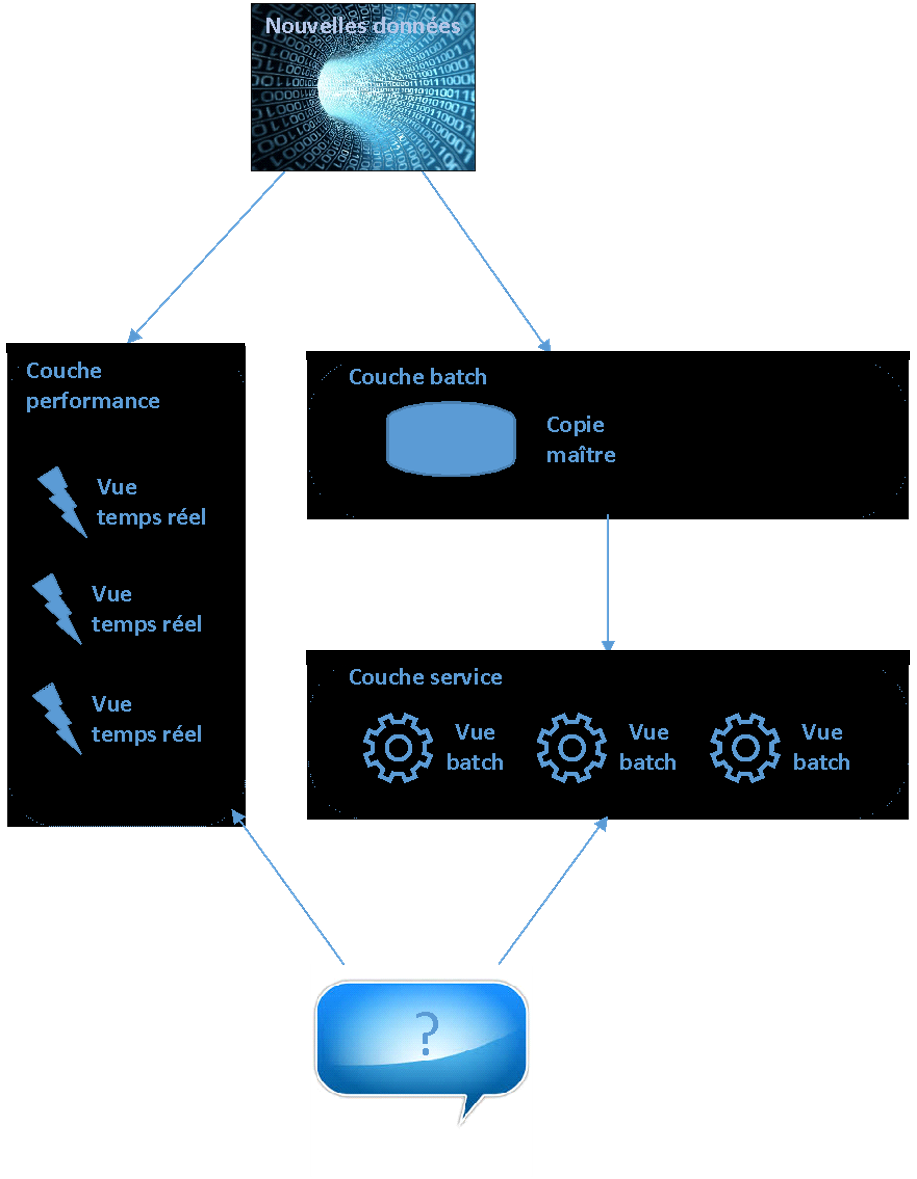
Figure 1 – Les 3 composantes d’une architecture Big Data de type Lambda
Couche batch
La couche batch stocke de façon distribuée une copie maîtresse de l’ensemble des données. La copie est immuable et croît constamment. Elle comprend des données structurées et non structurées brutes. Les données sont stockées telles quelles, sans dérivation ni transformation. Le fait de garder les données dans un format brut fait en sorte qu’il n’y a aucune perte de données et cela assure une plus grande flexibilité. Des calculs peuvent être refaits sans toucher aux données brutes. Par exemple, si un algorithme d’analyse sémantique s’améliore, il est possible de refaire l’analyse à partir des données brutes pour obtenir des résultats d’une plus grande qualité. Si seuls les résultats d’analyse avaient été conservés, nous n’aurions pas eu cette possibilité.
Par ailleurs, c’est la couche batch qui s’occupe du calcul des vues batch. Les vues batch sont le résultat de dérivations et de transformations de données brutes. Les vues batch simplifient la consommation de données et la rendent plus performante. Ces vues sont continuellement rebâties ou mises à jour, à partir de la copie maîtresse, au fur et à mesure que de nouvelles données arrivent.
Couche service
La couche service accède aux vues batch dès qu’elles sont disponibles, c’est-à-dire dès que le calcul (ou le recalcul) par la couche batch est complété. Comme pour la couche batch, il y a distribution sur des grappes de machine pour assurer l’évolutivité. Il doit donc y avoir une balance entre la quantité de précalculs de la couche batch et la performance des requêtes de la couche service.
Couche performance
Il peut y avoir des heures de latence pendant le stockage et le précalcul des vues batch avant que de nouvelles données soient disponibles. S’il y a besoin d’une latence faible (jusqu’à se rapprocher d’un traitement en temps réel), il faut compenser. Et c’est le but de la couche performance : rendre disponible les nouvelles données aussi rapidement que requis pour les requêtes.
La couche performance se veut donc une sorte de couche batch, mais seulement pour les données récentes. Elle produit des vues en temps réel qui sont mises à jour au fur et à mesure que des nouvelles données sont reçues. Elle utilise des algorithmes incrémentaux et des structures de stockage avec des contraintes de latence plus complexes. Mais cette complexité est isolée pour quelques heures de données seulement. Une fois la latence passée pour une nouvelle donnée dans les couches batch et service, la donnée correspondante dans la couche performance n’est plus requise.
Les requêtes de la couche service qui requièrent une faible latence vont alors typiquement combiner les vues batch et temps réel pour s’exécuter.
En somme, l’architecture Lambda est une pratique d’architecture Big Data qui sépare le stockage, la consommation et la complexité d’une faible latence. C’est une approche agnostique qui peut être utilisée avec différentes solutions technologiques Big Data, à quelques variances près dans le détail de son implantation.
Autres articles
Intelligence d'affaires
Ni temps-matériel, ni forfait rigide : le modèle de partage de risque d'agileSquad
Juillet 2026Etienne Faribault
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati