3 modèles: 3 façons de structurer les données, 3 raisons d’être
Une erreur commune consiste à comparer la modélisation transactionnelle, Data Vault et dimensionnelle et à prendre position sur celle qui soi-disant est la meilleure. La réalité est qu’il n’existe pas une meilleure approche pour tous les contextes. Chacun des trois types de modèle est le plus optimal dans son contexte. En fait, utiliser les trois approches de concert permet de profiter des forces de chacune.
Pour bien comprendre cette complémentarité, rappelons la finalité de chacune d’entre elles.
Modélisation transactionnelle
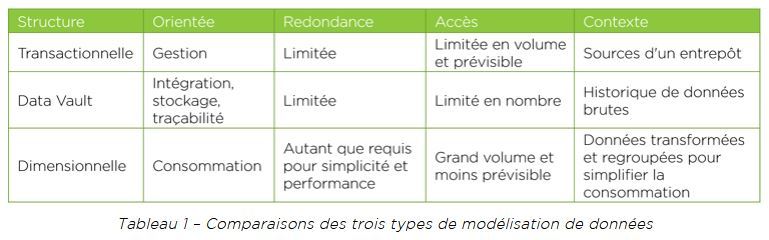
Le but d’un modèle de données transactionnel est de créer une structure de gestion (créations, mises à jour) des données. Pour faciliter la gestion des données, le modèle doit limiter le plus possible la redondance en les séparant en entités distinctes normalisées liées entre elles par des relations.
La structure est plus simple d’un point de vue gestion (moins il y a de redondance, moins on doit gérer celle-ci afin de garder la cohérence des données), mais elle est plus complexe pour l’accès aux données, puisqu’il y a un plus grand nombre d’entités et que les chemins d’accès peuvent être parfois assez complexes. En contrepartie, l’accès aux données est limité en volume et prévisible parce que répétitif (exemple : l’accès au profil d’un abonné dans un centre d’appel). Dans un contexte d’intelligence d’affaires, les structures transactionnelles sont celles de nos sources de données.
Modélisation Data Vault
Le but d’un modèle de données Data Vault est de créer une structure d’intégration des concepts (appelés « hubs ») et des liens interconcepts. Il permet également le stockage de l’historique des données décrivant ces concepts et liens interconcepts dans des structures satellites. Qui plus est, pour faciliter l’intégration et le stockage et assurer la traçabilité avec les sources en tout temps, le modèle ne contient aucune transformation de données.
La structure Data Vault est garante de l’historique des données de l’organisation ce qui n’est pas toujours le cas pour les données gérées dans les sources qui sont souvent moins intéressées par l’historique. La structure est optimisée pour le stockage, mais elle est moins adaptée pour une gestion opérationnelle précise et elle n’est pas non plus la plus optimale pour la consommation des données.
Modélisation dimensionnelle
Le but d’un modèle de données dimensionnel est de créer une structure de consommation des données. Pour faciliter la consommation de données, le modèle doit être conçu pour simplifier le plus possible les accès aux données qui se font souvent en grande quantité et d’une manière plus imprévisible, ce qui est typique des environnements d’intelligence d’affaires.
La structure dimensionnelle en étoiles, avec ses faits au centre et ses dimensions autour décrivant les faits, est la meilleure façon de structurer les données pour en faciliter la consommation. Elle permet, comme pour la structure Data Vault, de conserver l’historique des données, mais le stockage de l’historique peut devenir complexe, en autre pour les grosses dimensions et les différents cas de conformité.
Par ailleurs, l’intégration est plus difficile pour un nombre élevé de sources et la traçabilité est plus difficile à garantir, étant donné les transformations effectuées pour satisfaire de multiples règles d’affaires.
Le Tableau 1 résume les caractéristiques des trois types de modèles.
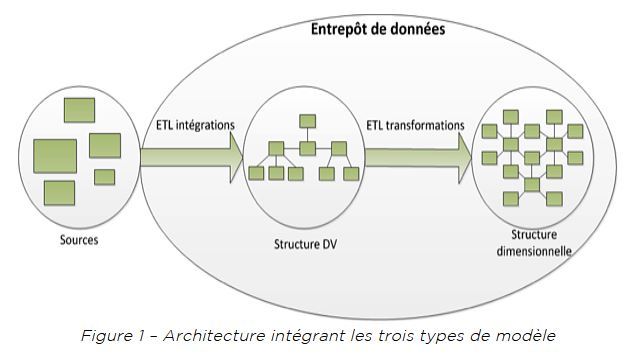
Une architecture intégrant les trois structures (voir figure 1) permet de profiter des forces de chacune. La structure des sources est normalisée pour simplifier la gestion des données dans un contexte opérationnel. Les données sources sont intégrées telles qu’elles et l’historique est accumulé dans une structure Data Vault. Les données du Data Vault sont transformées (par des règles d’affaires) et combinées dans une structure dimensionnelle qui simplifie une consommation des données diversifiée.
Autres articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati
Intelligence d'affaires
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
Mars 2026Adrien Chaudé et Adrien Lecellier